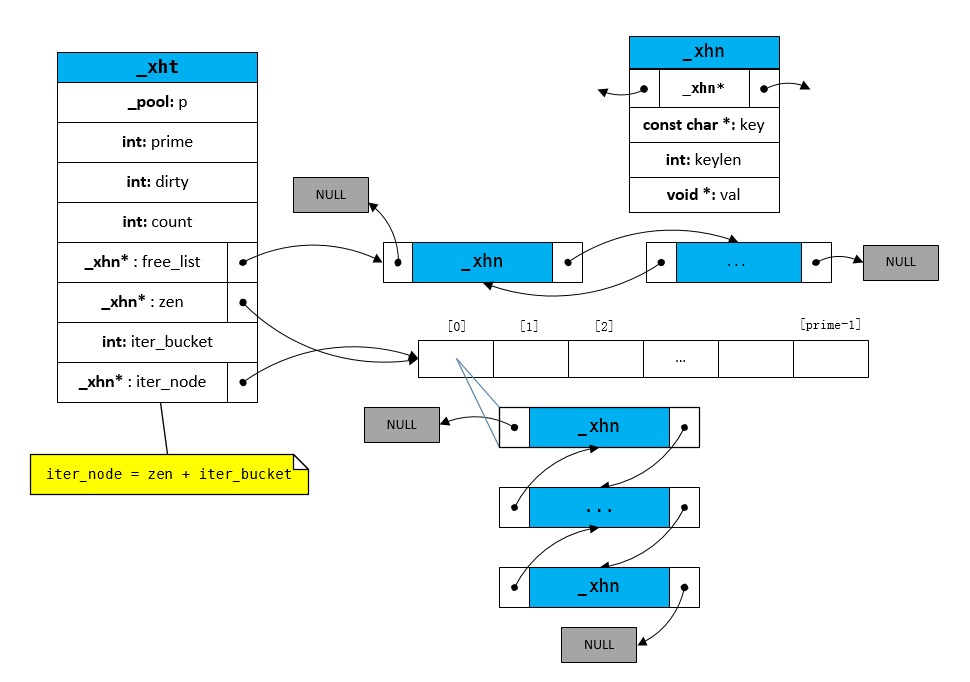
typedefstructxht_struct { pool_t p; int prime; int dirty; int count; structxhn_struct *zen; structxhn_struct *free_list;// list of zaped elements to be reused. int iter_bucket; xhn iter_node; int *stat; } *xht, _xht;
几个主要的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
staticint _xhasher(constchar *s, int len) // 生成hash值 { /* ELF hash uses unsigned chars and unsigned arithmetic for portability */ constunsignedchar *name = (constunsignedchar *)s; unsignedlong h = 0, g; int i;
for(i=0;i<len;i++) { /* do some fancy bitwanking on the string */ h = (h << 4) + (unsignedlong)(name[i]); if ((g = (h & 0xF0000000UL))!=0) h ^= (g >> 24); h &= ~g;
/* log_debug(ZONE,"creating new hash table of size %d",prime); */
/** * NOTE: * all xhash's memory should be allocated from the pool by using pmalloco()/pmallocx(), * so that the xhash_free() can just call pool_free() simply. */
p = pool_heap(sizeof(_xhn)*prime + sizeof(_xht)); xnew = pmalloco(p, sizeof(_xht)); xnew->prime = prime; xnew->p = p; xnew->zen = pmalloco(p, sizeof(_xhn)*prime); /* array of xhn size of prime */
voidxhash_putx(xht h, constchar *key, int len, void *val) { int index; xhn n;
if(h == NULL || key == NULL) return;
index = _xhasher(key,len);
/* dirty the xht */ h->dirty++;
/* if existing key, replace it */ if((n = _xhash_node_get(h, key, len, index)) != NULL) { /* log_debug(ZONE,"replacing %s with new val %X",key,val); */
voidxhash_zap_inner( xht h, xhn n, int index) { int i = index % h->prime;
// if element:n is in bucket list and it's not the current iter if( &h->zen[i] != n && h->iter_node != n ) { if(n->prev) n->prev->next = n->next; if(n->next) n->next->prev = n->prev;
// add it to the free_list head. n->prev = NULL; n->next = h->free_list; h->free_list = n; }
//empty the value. n->key = NULL; n->val = NULL;
/* dirty the xht and track the total */ h->dirty++; h->count--;