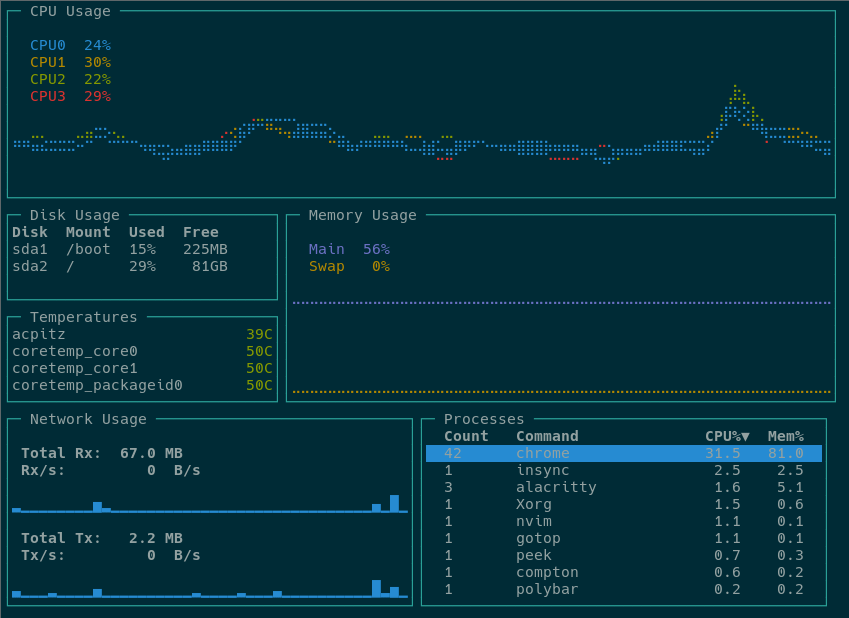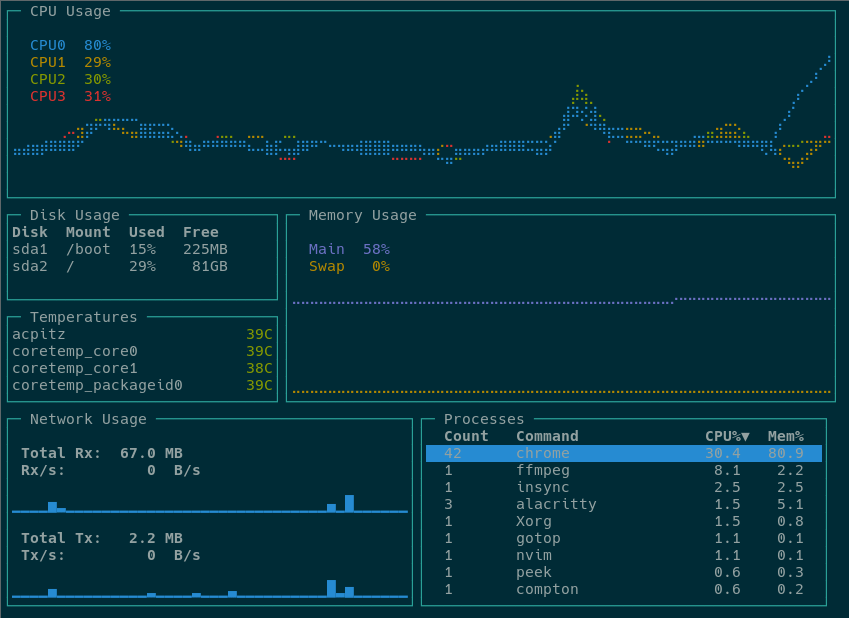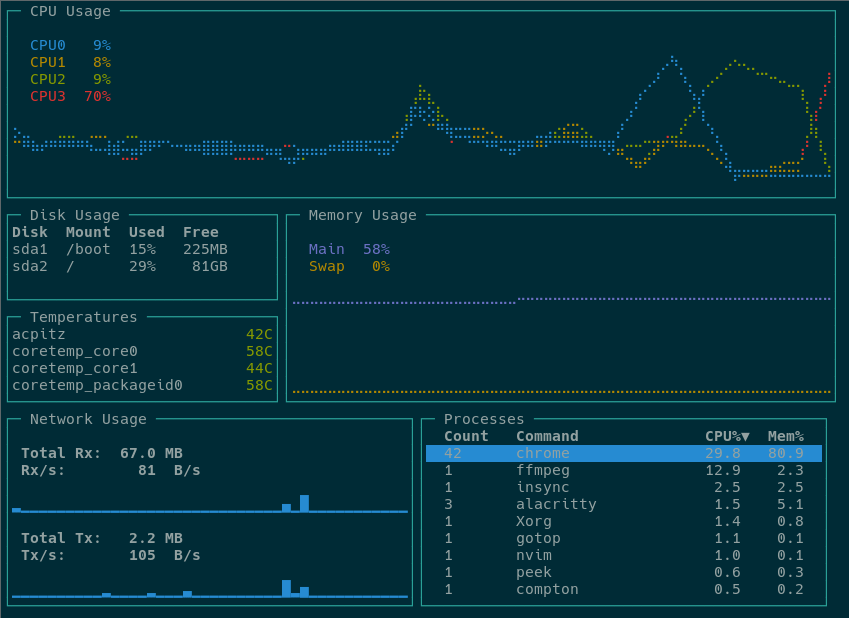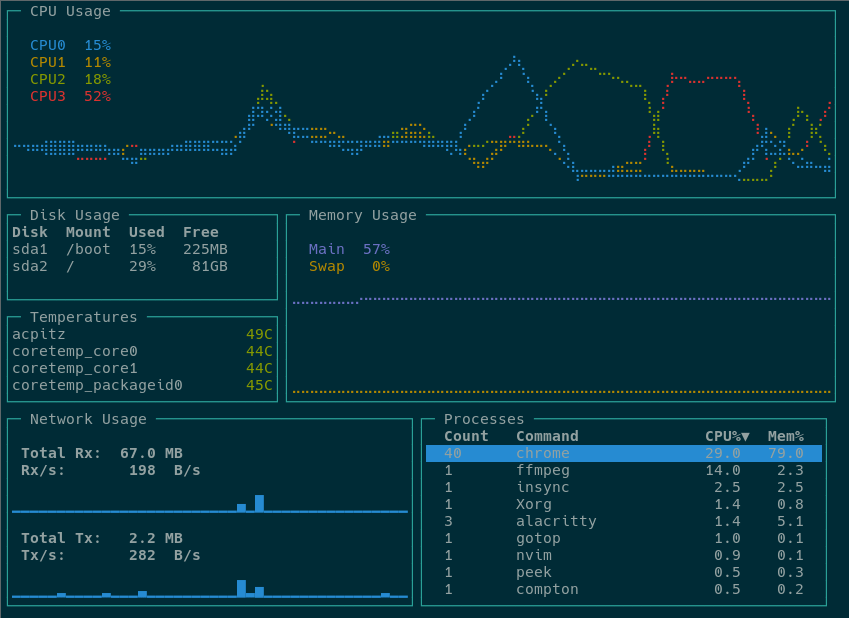
Here I want share some strengths of FILCO MINILA, especially the 2nd generation MINILA-R Convertible. So, basically these points are main considerations when I choosing a mechanical keyboard.
Layout & Built-in shortcuts
For me these are the most important consideration. It has direct impact on productivity, when it used by programmer, this effective comes double. I believe less finger move bring faster strike, that’s why I prefer compact keyboards. But not just the layout, the built-in shortcuts must came help for the arrow and other feature keys.
The MNILA-R Convertible inherit most shortcuts from last gen and imporve the built-in shortcuts support for Mac, like volume, screen brightness. Wow!
The DIP Switch, for me, I setup as the above picture. The most useful switch for me is replace CapsLock with Ctrl key. Before I switch it ON, I cannot figure why there is such thing. I turned it ON at one day four years ago, that feeling just hit me from deep mind. I’ve realized that I barely use CapsLock for all the time, more over, it set my little finger free, no longer to touch left corner for Ctrl key.
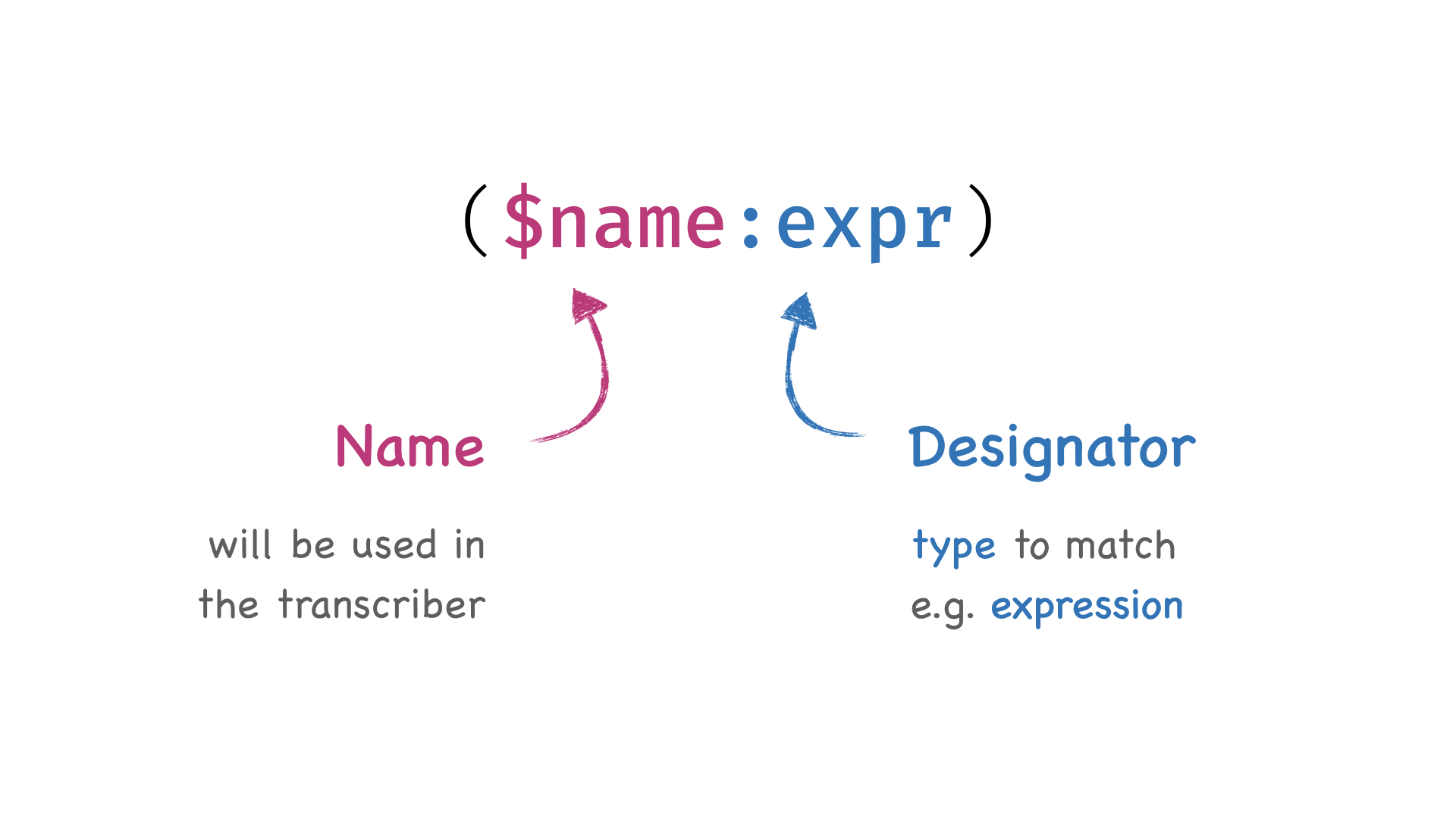
The Fn key position, it have two Fn key beside the Space key, very convenient for many shortcuts. That’s why I prefer it to HHKB. Here is the original description of Fn key by FILCO:
The world’s first double function keyboard!
Majestouch MINILA is the Mini layout version of Majestouch and we’ve made it as compact as possible by sharing Function keys with other keys. It has the same key pitch as our famous Majestouch keyboards.
The most striking feature of MINILA is the “Double Function keys” located each side of the spacebar. We focused on less frequently used finger, the thumb, and let it work with Function keys. Just keep your thumbs busy and you get a lot of work done much easier than a normal keyboard! You can use whichever thumb you want. This keyboard can work well for anybody! Professionals, intermediate or even beginner class!Once you get used to typing on MINILA, you will not want to go back typing on normal keyboards!
[You can use MINILA even more conveniently with FN keys]
You can type cursor keys with a combination of FN key.
Pressing FN key and E/S/D/F simultaneously corresponds to ↑/←/↓/→ respectively.
With this solution, you can keep your home position and still you get to type arrows very easily.
Pressing FN key plus [:;] key simultaneously functions as backspace.
This will allow you to command backspace without changing your home position.
Those combinations will offer you a faster typing environment.Keycap
The MINILA-Air’s keycap is what attracted me in first place. It is made by ABS, but the sense of touch is a icy feeling and smoothly. To keep that feeling I keep clean the keycap surface before it come to greasy. Then I tried to replace them by PBT keycap. After a few month, I change back to original keycap, miss that feeling.
The MINILA-R Convertible keycap is a so called ‘Patch Keycap’ made by PBT. So the touch area is a litter smaller than MINILA-Air. It doesn’t like other frosted feeling PBT stuff, keep the glossy surface from last generation. It still be greasy after years using, but much slower.
Battery
If someone around you used FILCO, then you’ve must heard of its battery life. Just load the AA batteries in, then forget it. For years I can’t believe it’s powered by AA batteries and I don’t know how it accomplish that. It seems have nothing to do with bluetooth version(1st: v3, 2nd: v5.1). In contrast, some keyboard with lithium battery pack(Niz Keyboard), only stand for few months, and I have to plugged it in frequently, finally it becomes a USB cable keyboard.
Multiple Connections
I switch devices often, it was a pain suffer. MINILA-R Convertible had done a great of that by just add 4 devices key, and moreover, it had a USB 2.0 connection!
The 1st Gen MNILA Air had some connection issue every time reconnect to a device(Chances, especially hit Cmd key during connection initialization, key comes to Alt code). The issue is gone on MINILA-R Convertible and more smoothly.
Appearance
I like simple color, my first mechanical keyboard is MINILA-Air in black, then the white. In 2020 MINILA-R Convertible came out with Sky Gray/Black/ASAGI color, the ASAGI color is a kind of blue, looks better than two. FILCO seems like mod colors. Unitl the MINILA-R Convertible anniversary, the white color finally came out(above picture). The white part like some kinde of baked paint, shining and beauty.
It was fortunate that no light in MINILA. RGB lights are totaly not necessary for keyboard.
Switch
This is the most trivial part, because many mechanical keyboard manufacturers do use the Cherry MX Switch. MINILA-R Convertible add MX SILENT Red switch, which became my favorite one. Before that is MX Red switch, but the new MINILA-R Convertible’s red switch distance of strike is clearly shorter than MINILA-Air.
These are my share review of FILCO MINILA, hope you can find your best mechanical keyboard.😀
]]>